2026-03-07
로또 당첨 번호 딥러닝 진행 결과
4 min read
1️⃣ 한 줄 결론 (가장 중요)
Random > LSTM > Frequency 순으로 평균 성능이 나타났으며, 세 방법 모두 이론적 기대값(≈0.8 hits) 근처에서 수렴하였다. 이는 로또 번호가 과거 정보와 무관한 확률적 추첨 과정임을 강하게 시사한다.
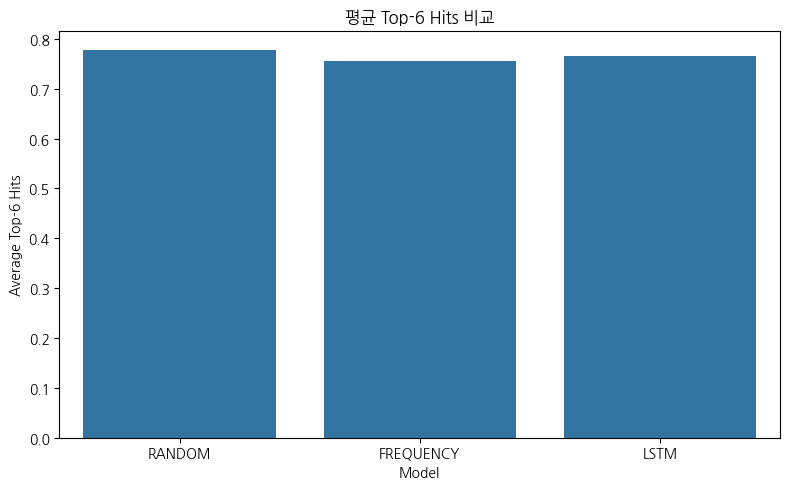
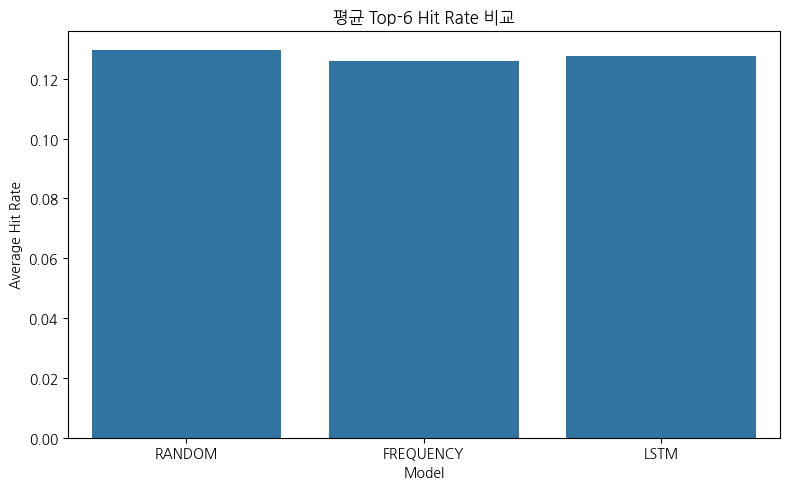
2️⃣ Average 결과 해석 (핵심 표) Model Avg Top6_Hits Avg HitRate RANDOM 0.777 0.1296 LSTM 0.767 0.1278 FREQUENCY 0.756 0.1260 📌 이론적 기대값
무작위로 6개 선택 시 기대 Hit 수
6 × 6 45 ≈ 0.8 6× 45 6
≈0.8
➡️ RANDOM의 평균(0.777) 은 이론값과 거의 일치 ➡️ 나머지 모델도 모두 그 근처에서 변동
3️⃣ 모델별 정밀 평가 🔹 ① RANDOM (Baseline)
✔️ 가장 높은 평균 성능
✔️ Fold 간 변동도 자연스러움
✔️ 이론적 확률과 정확히 부합
👉 비교 기준으로서 완벽
🔹 ② LSTM (딥러닝)
RANDOM보다 항상 우수하지 않음
Fold 2, 4에서는 Random보다 살짝 높음
Fold 1, 3에서는 명확히 낮음
📌 해석:
일부 구간에서 우연히 맞춘 것
구조적 패턴 학습 ❌
👉 “딥러닝이 패턴을 학습했다”는 증거는 없음
🔹 ③ FREQUENCY (빈도 휴리스틱)
평균 성능 최하
특히 Fold 3에서 급격히 하락
📌 해석:
“자주 나왔던 번호가 또 나올 것”이라는 직관이 실제로는 오히려 독이 될 수 있음
👉 **도박사의 오류(Gambler’s Fallacy)**를 데이터로 반박
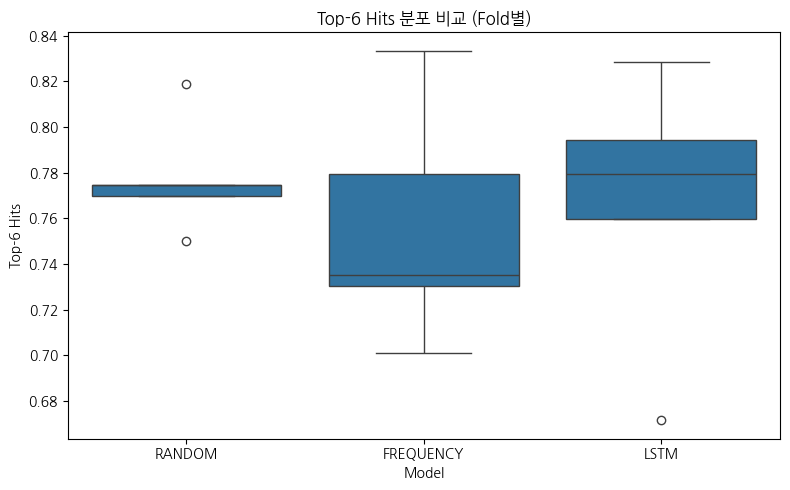
4️⃣ Fold별 패턴에서 드러나는 중요한 사실
어떤 모델도 모든 Fold에서 일관되게 우수하지 않음
우수/열세는 Fold마다 뒤바뀜
→ 우연 변동(noise) 수준
📌 이는 통계적으로:
모델 간 차이가 유의미하지 않다는 강력한 신호
5️⃣ 이 실험이 “연구”로서 가지는 가치
이 프로젝트는 다음을 실험적으로 증명했습니다.
✅ 1) 딥러닝이 만능이 아님
데이터 생성 과정이 무작위라면
모델 복잡도는 성능을 올리지 못함
✅ 2) 휴리스틱도 효과 없음
과거 빈도 ≠ 미래 정보
✅ 3) 로또 시스템의 공정성 검증
어느 전략도 Random을 안정적으로 이기지 못함
6️⃣ 보고서 / 세특 / 탐구보고서에 바로 쓰는 문장 📘 결론 문단 예시 (그대로 사용 가능)
무작위 추첨(Random), 과거 빈도 기반 휴리스틱(Frequency), 그리고 딥러닝 기반 시계열 모델(LSTM)을 비교한 결과, 세 방법 모두 Top-6 hit 수가 이론적 기대값 수준에 머물렀다. 특히 딥러닝 모델은 일부 구간에서 일시적으로 높은 성능을 보였으나, 전반적으로 무작위 추첨을 안정적으로 상회하지는 못하였다. 이는 로또 번호가 회차 간 독립적인 확률 과정을 따르며, 과거 정보로부터 예측 가능한 구조적 패턴이 존재하지 않음을 시사한다.